March 4 / 2026 / Reading Time: 7 minutes
Wrongfully Accused: AI and the Death of Cyber Security
The Scene of the Crime (?)
On a cold February morning (at least, on the East Coast), the world awoke to a post by AI company Anthropic that their flagship product, Claude, was finding security vulnerabilities at an alarming rate (https://red.anthropic.com/2026/zero-days/). With a headline that provoked both fear (“…growing risk…”) and hope (“mitigating ….”), the story skillfully laid bare the capabilities of AI to find security vulnerabilities..
The cyber security industry soon began to feel the weight of this accusation: Stock prices fell, people took to social media to speak out in defense of a field still finding its way, AI investors rubbed their hands with glee that confirmation of their belief was being proven, and the CEO of one of the largest cyber security companies went directly to AI and asked it just what it was capable of in an effort to counter the accusations (read about that here).
Before anyone could blink, social media was ablaze with statements piling onto the accusations. Cyber security was dead! And who was standing at the center of it all? AI.
However, all is not as it seems. Our investigation reveals a different picture. Join us as we unravel this heated discussion to find out if cyber security really is dead, and if AI is the murderer.
When you hallucinate, it's normally a problem….
First, let’s start with a thorough reading of Anthropic’s post.
A quarter of the way into the post, tucked away into the Setup section, Anthropic states:
To ensure Claude hadn’t hallucinated bugs…we validated every bug extensively before reporting it.
“Hallucinated bugs,” in laymen’s terms are mistakes. They’re “invented problems that don’t exist.”
How often does AI hallucinate you may be wondering? This is still being examined, but some data suggests LLMs hallucinate 7-16% of the time.
So, roughly 1 in 10 answers will be errors, if you’re lucky. What did Anthropic do to address this? Well it's right there in their post: “we validated every bug extensively before reporting it.” They don’t say here that humans validated Claude’s findings, but later they do: “our own security researchers validated each vulnerability and wrote patches by hand.” How long did that take for 500 bugs? Who knows, but you can be sure it wasn’t 1 hour. 500 bugs found by AI, but every single one validated and remediated by a human.
AI found security vulnerabilities. Does this mean cyber security is dead? Let’s dive in a little more to how AI works to see if its truly capable of taking out this entire industry.
The House Always Wins
Let’s start with a universal truth: AI doesn’t know facts. While this claim may shock you, when you look at how Large Language models (LLMs) work, you’ll find LLMs are probabilistic in nature, and that is why they cannot know facts.
Think of a game of blackjack...
A good blackjack player has a strategy, one based on math. The strategy says if you have 16 and the dealer shows a 10, you should hit (or take another card). This is based on likelihoods, or probabilities, that give you the best chance to win.
LLMs operate the same way. After analyzing billions of sentences, they end up with a giant graph that says, if the sentence starts with “the cat sat on the…”, then the next word is mat. The LLM has no idea what a cat or mat is; it’s just playing the odds.
Back to blackjack. The house always has the edge (otherwise, Vegas would just be an empty patch of desert). You can play the odds perfectly, but the dealer still wins. Similarly, the LLM follows its chart, picks a word that looks right (i.e., statistically probable) but is factually wrong. That’s a hallucination. The LLM played the hand correctly as per its math (i.e., programming and training), but the answer was wrong.
Ultimately, an LLM does not think. That’s why it will always follow the rules to hit on 16 when the dealer has 10 (unlike human players, plenty of whom will stay and play their odds). An LLM will merely calculate its odds, and play according to its math. And there will be times where it’s wrong, and the house will win.
Explainer video below
This is the default inherent nature of an LLM, it cannot change, and it further explains why those humans were needed to validate the potential security vulnerabilities. It also begs the question if 500 were reported, how many were found but wrong?
Are there any other possible clues which point to AI’s guilt?
From RAGs to Riches?
What if you could remove that house edge we talked about and show AI to be our culprit? (This is the last of our casino analogies, promise!).
There are various approaches that can make AI more accurate. The two main ones are:
- Retrieval Augmented Generation (RAG)
- World Models
RAG is like giving AI a book, or a library, to help increase the odds that you get the right answer, since this gives AI facts.
When thinking about Anthropic’s findings, maybe they gave Claude some technical guides on finding bugs, such as the still legendary The Art of Software Security Assessment by Mark Dowd. Great! Knowledge gap solved. But reasoning still remains a challenge. In other words, the LLM still doesn’t understand the context for these facts.
This RAG approach decreases the chance of the model inventing facts out of thin air, but the context can still be flawed. And RAG comes with other concerns:
The user asks a question, but the system retrieves the wrong document (the “retrieval miss”) so the answer is hallucination free, but it’s also factually wrong.
LLMs have a strange quirk about where they place their attention. If the RAG has 10 documents for context, research shows LLMs pay attention to the beginning and end of the list. What if the really important piece of information is in the middle? The chance of hallucination increases.
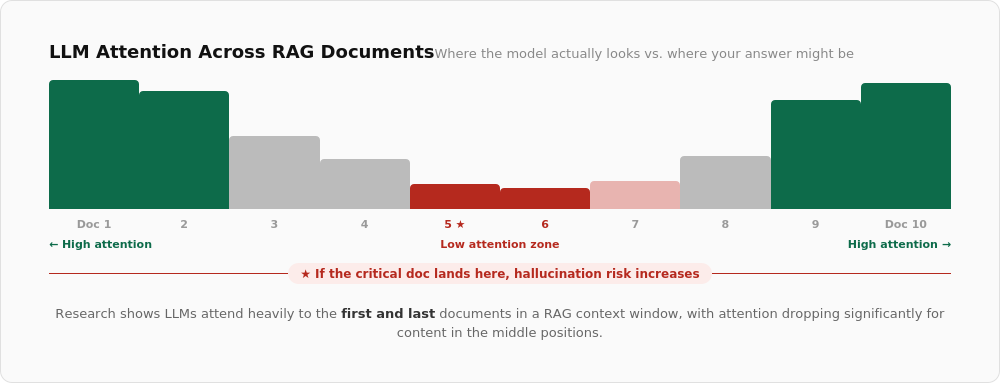
Some models are also sticky with regards to their training data. This means the model fails to adhere to your context. How does this work? You give the model a new company policy that contradicts industry standards. The model’s output is based on industry standards, because the probabilistic weight of their training is stronger than the context they receive from you. How would this work, then, in cyber security, which has dozens of standards and frameworks and regulations, but most are meant to be customized to each organization’s unique environment?
RAGs also introduce security issues. In a corporate environment the RAG may connect to a database. If permissions are set incorrectly (which they often are), a user could ask a question that retrieves a document they shouldn’t have access to (e.g., salary data, board information). So now you have a data security and privacy issue.
RAGs can reduce the hallucination rate to something more manageable (maybe a 50% decrease in factual errors). However, the tradeoff shifts between the accuracy of the model (did it lie?) to the data engineering (did it retrieve/read/use the right doc to get this answer?). If your search is bad, your AI can become a confident liar with a bibliography.
A Smoking Gun: World Models?
Let’s look at another approach that helps AI’s accuracy: world models. This may be the nail in the coffin for the case of AI killing cyber security.
World models provide AI with a representation of how the world works. This includes rules of causality (if I drop a glass, it breaks), so there’s no need to statistically guess the next word. This means AI “knows” the outcome based on the rules of its model, so the risk of mistakes is reduced. This is an attempt to mimic human reasoning (i.e., thinking before you speak).
Grounding AI in reality gets us closer to affirming that AI can kill cyber security: While an LLM can hallucinate a legal precedent, a world model would simulate the legal system and its logic, so if a generated answer doesn’t fit the model, it’s rejected. LLMs lack common sense by default, but a world model puts the rules of a system into place. World models are the current leading theoretical solution to the limitations of LLMs.
In cyber security, a world model can enable AI to understand the nature of an organization, the technical details, how applications are used, and other factors that make up the environment in which it is operating.
So, if world models let AI simulate how humans reason, and remove hallucinations, is this the smoking gun we have been looking for?
Unfortunately, no.
Let’s go back to that statement about a world model providing the facts an AI needs to understand an environment. Now, ponder how much data that would have to be, and, in most organizations, how easy that data is to find?
You’ll need to provide the data for an accurate simulation of your environment — every asset, business process, user, vulnerability, piece of code, etc. Then you also need behaviors for that system. Think of your own behavior on any given day; now write down a model which provides all the details about that behavior mapped to your systems. Now, go and build this for each department — finance, HR, engineering, IT, marketing — and all your infrastructure, from stuff in the cloud to mobile devices and more. And don’t forget to map how people purchase and use unsanctioned apps (the infamous “shadow IT”). In the real world most organizations do not have an accurate asset inventory, let alone all that data. And if the data is wrong, then the world model will be wrong, and any answer you get from the AI will be wrong.

When you understand how AI works today, and the technology underpinning it, the idea that AI can perform security alert and analysis, implement behavioral analysis, and serve an attack detection system seems premature at best. Sure, it can review alerts much faster than a human analyst. However, without an organization’s detailed world model, the AI is taking its best probabilistic guess at what it’s seeing. And we can see how difficult it would be to provide an accurate world view.
Verdict: Cyber Security is Not Dead; AI is Not Guilty
Hallucinations, RAGs, World Models: everything points to AI being wrongly accused of killing cyber security.
There’s no way, effectively, for AI to replace current cyber security solutions. At best it can help as a force multiplier. It can find hundreds of possible bugs, but without deeper analysis ( aka, humans) all you end up with is a bunch of noise. The economics of which would make any CFO pause. Yes, AI can do some of the work — maybe of a junior employee — but even this is proving to be questionable. It’s practically impossible to fix this with LLMs. Anyone who tells you otherwise doesn't know how LLMs work (and is probably trying to get a good commission.)
AI doesn’t fix cyber security, and it certainly hasn’t killed it. Instead of the software bug hunter looking for needles in a haystack, they now get to judge which needles your AI bot found are real.
What AI actually does is make your cyber security problem much worse, but more on that next time, when we’ll discuss AI and the death of zero trust (a crime it actually did commit).